BUAA-OO-第三单元:规格化设计
BUAA-OO-第三单元:规格化设计
【小女子废话较多,总是“有感而发”地“抒情”,这些不重要的话用“【】”标注出来了,可以尽情跳过~】
前言
本单元的主题是“规格化设计”,要求我们学会理解 规格语言,并能基于规格编写代码实现相应的功能。
在我看来,课程组在设置本单元的时候,初衷并不是要求我们完全掌握使用 这一语言,毕竟 只是一种特殊的规格化语言而已,还存在许多其他规格语言,例如: 规格语言、 规格语言等等。相对而言,课程组的目的应该是让我们在“面向规格编程”的过程中感受到“契约式编程”的魅力——高可靠性、高可复用性、便于测试 …
从难度来看,本单元的三次作业都比前两个单元要简单很多,只需要根据课程组提供给的规格进行编程即可。但是,规格仅仅是一种契约,针对一种特定的规格可能会有很多实现方法,因此我们在编程时还需要特别注意代码运行的效率,否则很容易TLE。【非常令小女子心痛的是自己就出现了一次TLE,并且是较简单的思维盲区】
有关 规格描述语言的简单学习见王浩羽大佬的整理 ,这一点推荐可以提前浏览看一下,不要求完全掌握书写能力,但至少需要“看得懂”。
- 【注】:参照课程组撰写博客的要求,为了符合我博客的阅读思维顺序,我将课程组要求撰写的四大点内容进行了如下的重新排序(前言 部分就是 “本单元学习体会”):
- 谈谈自己对规格与实现分离的理解
- 思考OK测试对于检验代码实现与规格的一致性的作用
- 梳理本单元的架构设计,分析自己三次作业的图模型构建和维护策略
- 分析本单元的测试过程
规格与实现分离
规格描述 ==> 编写代码
-
方法一:借鉴 的实现逻辑编写代码
例:

-
方法二:采用其他算法或模型设计来优化实现规格描述的程序运行效率
例:

-
方法三:不要把实现某方法的过程局限在该方法内实现,而是可以借助其他多个方法的部分处理,实现“见缝插针”地完成任务目标
例:

【附】:上述的三个方法中最值得注意的是“ 方法三 ”,它暗藏的思维本质就是规格与实现分离。
规格与实现分离的涵义
规格与实现分离实际上暗藏了两层分离含义:
-
规格里的数据属性与实现不同
写规格是一件比较弯弯绕绕的事情,有时需要构造许多中间数据才能把一个事情说通,否则规格会非常复杂。
-
规格里的方法和实现方法不同
规格化设计只是一种 “设计”,具体实现不一定要这样实现,可以自己实现一些规格之外的方法,方便业务代码的实现。
-
强调规格只是一种“设计”
-
具体实现是需要从工程角度进一步优化
-
根据规格描述编写代码的注意点
- 不能盲目照抄 规格描述的实现代码
- 可能导致正确性出问题
- 可能导致运行效率降低
- 注意 规格描述中的潜在条件
- 完全翻译规格是 方法干的事情
OK测试方法
本单元三次作业中都涉及到了对不同方法编写 进行检验,同时也是作为对比理解规格与设计分离,因此这里我单独里列出对于 测试方法的理解和注意事项。
注:有些同学在 方法里调用了自己的
query方法,然后比较自己的query方法和 方法传入参数是否一致,一定要清楚前面这种方法是==错误==的!!
OKTest方法的定义
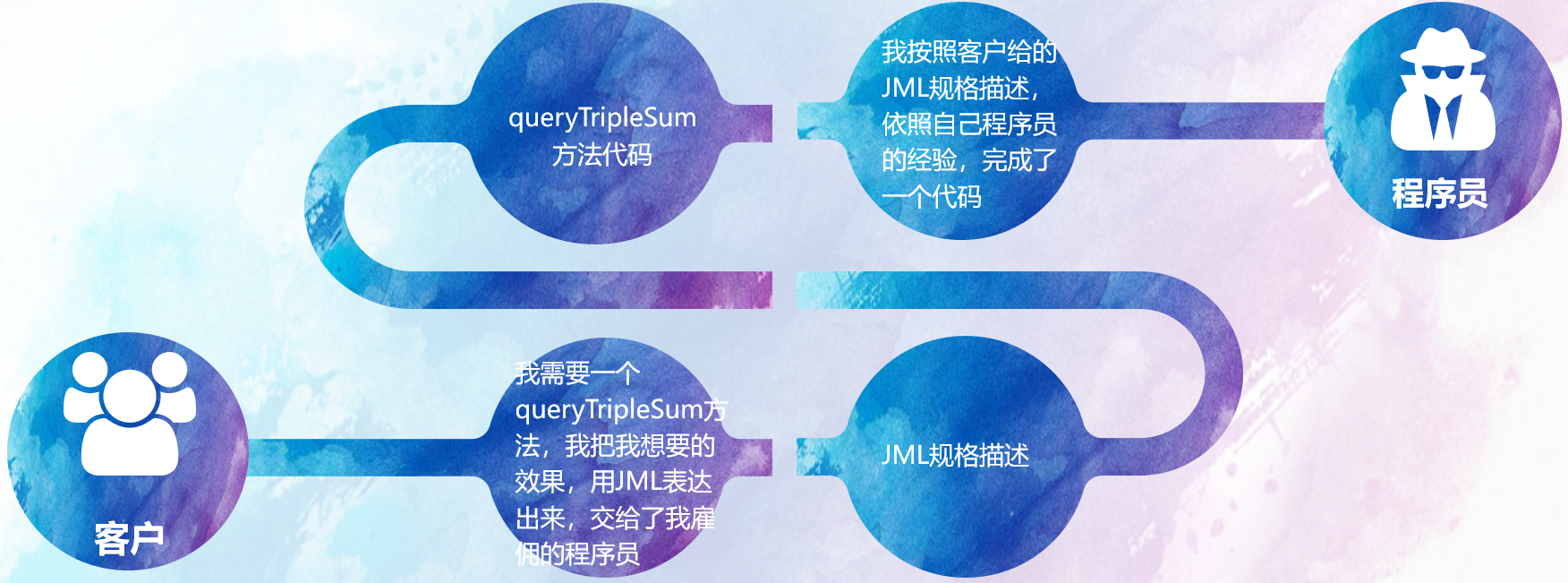
为了理解 方法到底是什么,这里我画图协助思考:
-
首先,我们要明白 客户 ---- JML ---- 程序代码 ---- 程序员 这一流程
-
那么, 方法就是一个第三方视角来评判上述整个流程的有效性

【在本课程中,我们在这里兼任 “程序员 + 上帝 ” 的角色身份哟~ 双重身份谍中谍的帅气~】
OKTest方法的实现
方法实际上可以看做是有一定模板的,本质就是完全一模一样地翻译 规格描述即可。具体而言,就是针对下面几个规格进行检验:
-
/*@ assignable @*/逐一验证除了
assignable中的实例变量之外其他实例变量是否在调用方法前后等值不变 -
/*@ ensures @*/需要依次逐一验证
ensures的后置条件 -
/*@ invariant @*/验证实例变量是否不为
null -
/*@ pure @*/比较在调用方法前后,实例变量的值是否没有变化,若产生了变化,则 方法需要报错
- 对于
int类型等变量可以使用==来进行等值验 - 对于
String、HashMap等类型变量可以使用.equals()方法进行等值验证 - 对于自定义类型的变量,如果想使用
.equals()方法,需要重写hashCode()函数
- 对于
合格OK方法的注意点
- 不能用任何逻辑和数学的推导
- 必须直观地和 描述效果一模一样
第九次作业
本次作业共三个任务:
- 根据官方提供的
Network和Person这两个接口进行代码设计,实现简单社交关系的模拟和查询; - 实现4个异常类;
- 实现
queryTripleSum的 方法。
UML类图
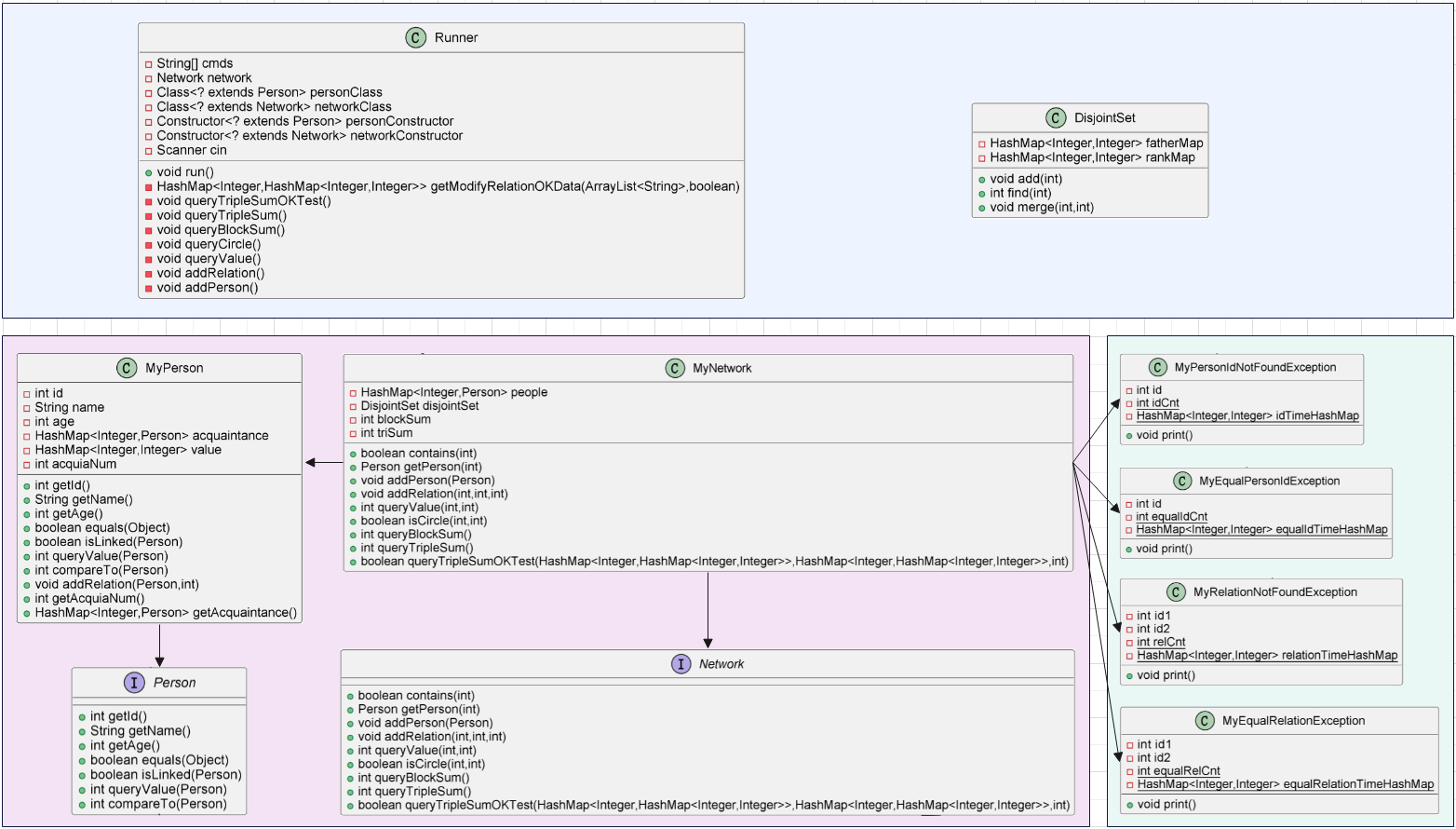
架构优化
容器
规格描述中给出我们需要定义数组,所以在 中我们需要思考究竟使用什么容器呢?常见的容器是 、 ,具体分析两种容器:
-
- 问题一: 查询元素时需要遍历,时间复杂度 ;
- 问题二:没有充分利用已知信息的特点,浪费信息有效价值。
-
- 优势一:将id作为键值,查询元素时时间复杂度为 ;
- 优势二:充分利用了每个
person的id唯一这个信息,实现信息的有效价值。
综上,我选择以 id 为 key ,对应的 person 为 value ,建立。
动态维护连通块计数
本次作业我们需要查询如下两个性质,为了避免每次查询都要重新计算一遍结果,我选择在每次 ap和ar 之后实时动态更新 Block 和 Triple 的数量:
public int queryBlockSum();public int queryTripleSum();
并查集
本次作业的重点实现函数是 public boolean isCircle(int id1, int id2); 为了提高性能,这里我使用了并查集结构。
-
并查集的定义:
并查集的重要思想在于,用集合中的一个元素代表集合。
一个有趣的比喻:把集合比喻成帮派,而代表元素则是帮主。每次比武,大侠总会请出帮主代表他们作战。
-
并查集的实现:
为了更好的符合“面向对象 ”的设计思想,将并查集封装成类,在类中用
HashMap来存储结点的父子关系,用find()、merge()、add()等方法封装并查集的相关操作。 -
并查集的优化:
- 路径压缩
- 目的:我们只关心一个元素对应的根节点,那么希望每个元素到根节点的路径尽可能短,最好只需要一步。
- 实现:只要在查询过程中,把沿途的每个节点的父节点都设为根节点即可。
- 按秩合并
- 目的:为了到根节点距离较长的节点个数尽量少,我们可以把简单的树往复杂的树上合并。
- 实现:用一个**数组****rank[]**记录每个根节点对应的树的深度(如果不是根节点,其rank相当于以它作为根节点的子树的深度)。
- 路径压缩
第十次作业
本次作业共四个任务:
- 更新
MyPerson、MyNetwork两个类的功能和方法; - 根据官方提供的
Group和Message这两个接口进行代码设计,新增实现群组、消息的结构; - 添加5个新的异常类;
- 实现
modifyRelation的 方法。
UML类图
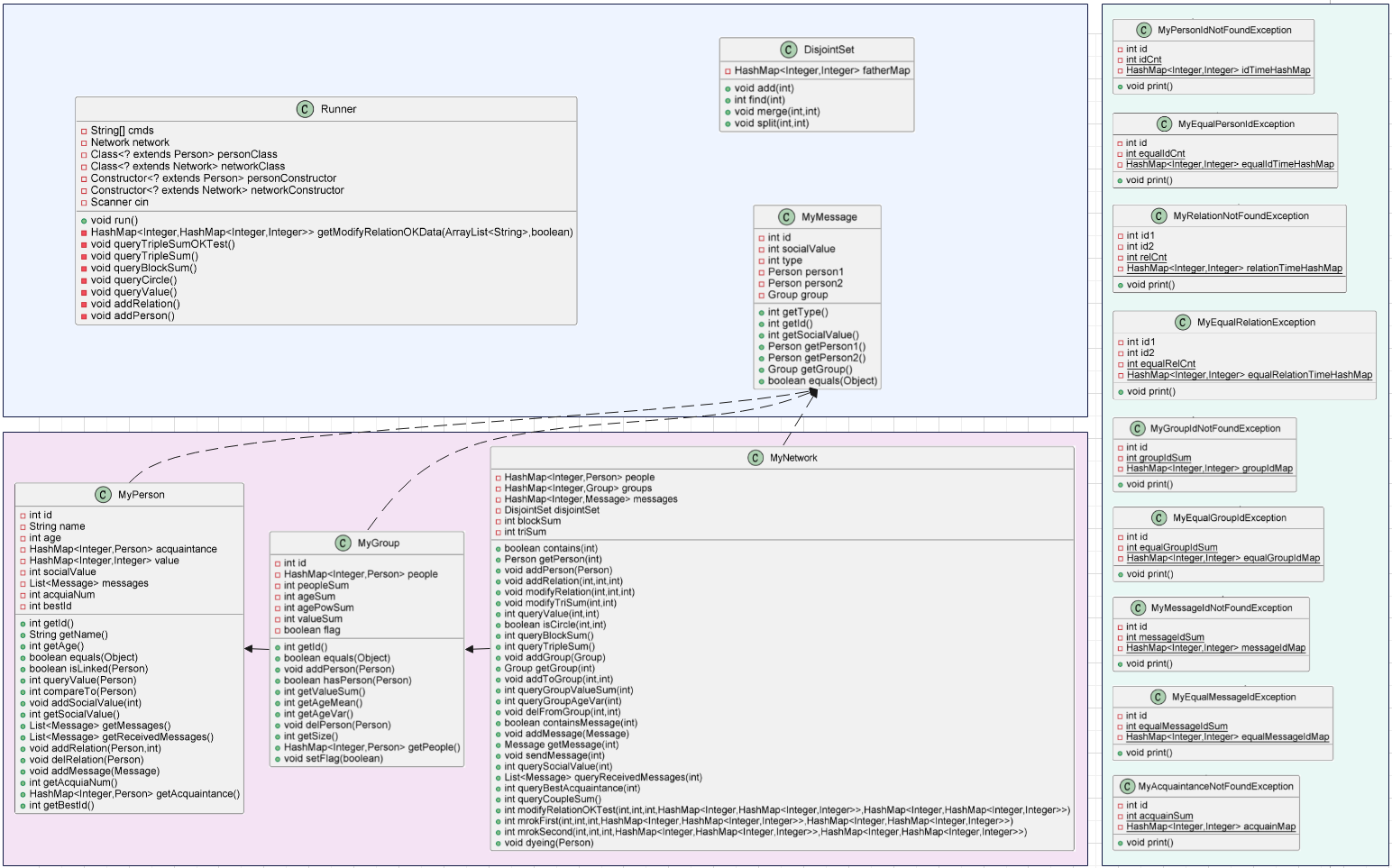
架构优化
计算类函数
本次作业一共涉及到两个计算类函数:
public int getAgeMean();public int getAgeVar();
两个计算类函数都是在动态维护变量 ageSum、peopleSum 的基础上,直接计算并返回结果,但是需要注意的是判断除数 peopleSum 是否为0。
动态维护并查集
本次作业的难点在于,方法 modifyRelation() 导致了可能会删除某些边,那么此时该如何使用更高效的方法来判断 Block 是否增加或不变呢?
在高揄扬大佬的细心讲解下,我使用了动态维护并查集 的方法,时间复杂度约为 。
-
方法核心:
前提:将上一次作业中对并查集的按秩合并优化删除。
当在
modifyRelation()中检测到需要删掉某条边的时候,就对这条边的两个端点进行 染色,通过判断染色结果来确定设左边点的id为leftId,右边点的id为rightId。- 首先,将并查集中的
father[rightId]设置为null; - 接着, 遍历并查集将所有与点
leftId相连的点的father[]标记为leftId; - 然后,检查并查集中的
father[rightId]是否为leftId。如果father[rightId] != leftId,则blockSum++;反之,blockSum不变。 - 最后, 遍历并查集将所有与点
rightId相连的点的father[]标记为rightId。
- 首先,将并查集中的
-
方法优势:
尽可能保留了并查集的架构设计,不影响其他需要使用并查集条件判断的方法。
第十一次作业
本次作业共四个任务:
- 更新
MyPerson、MyNetwork两个类的功能和方法; - 根据官方提供的
EmojiMessage、RedEnvelopeMessage和NoticeMessage这三个接口进行代码设计,新增继承MyMessage的子类; - 添加3个新的异常类;
- 实现
deleteColdEmoji的 方法。
UML类图
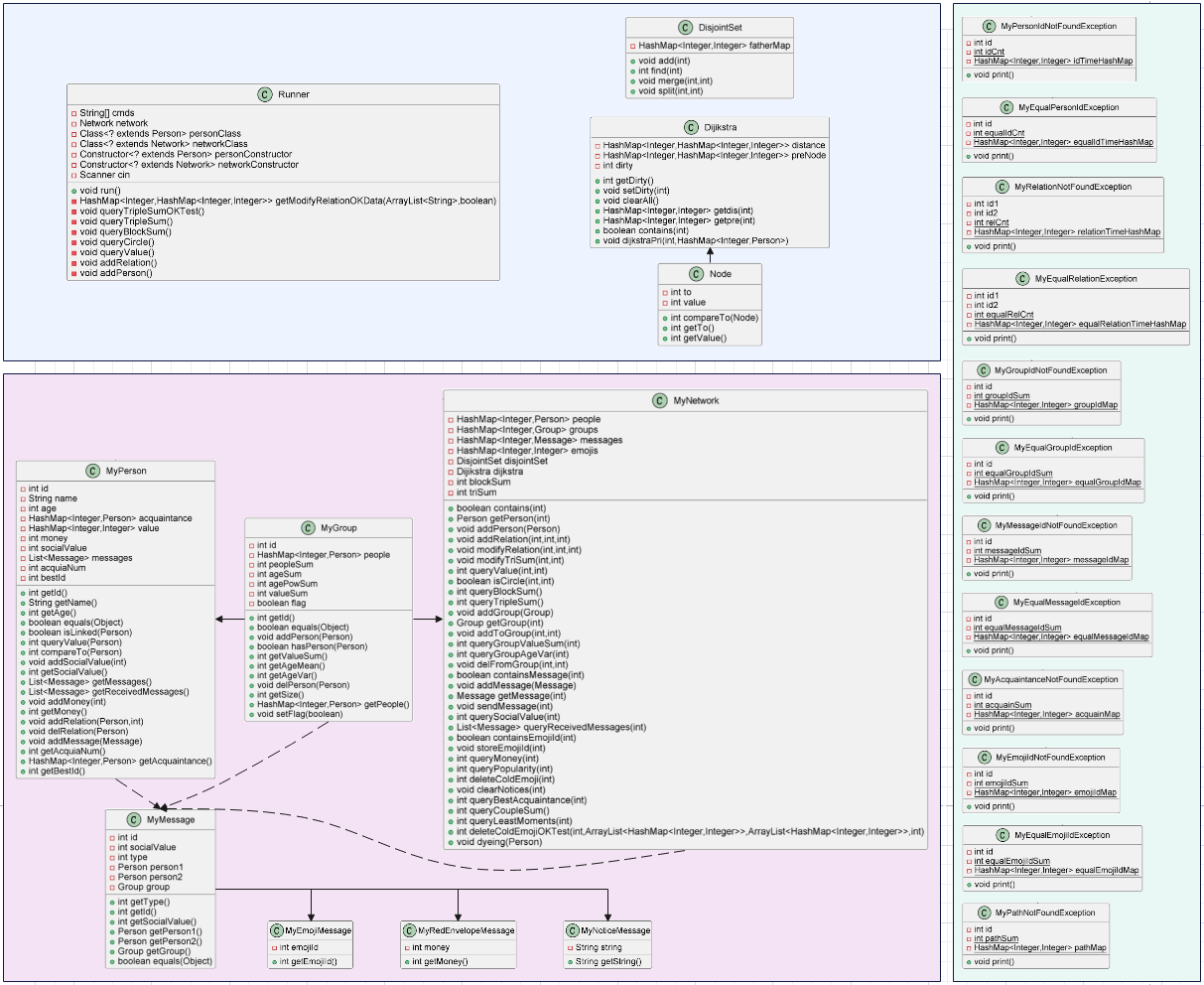
架构优化
最小环求解 = 最短路径求解 + 额外附加操作
要求包含点 id 的最小环,应该是 id 到其余点的最短路的边加上一条不是最短路的边,因为单纯靠最短路并不会形成环。
-
方法核心思路:
-
首先,我们先构造出以
id为根,以id到其余点的最短路为边的生成树; -
然后,我们将每两个不同的点看成一个组合,则这个组合必定满足以下两种条件任意其一:
- 这两个点中有一个点是
id; - 这两个点都不是
id;
- 这两个点中有一个点是
-
接着,我们发现可以按照上述的分类条件分别求解是否是最小环:
-
若两个点中有一个点是
id 查最短路径生成树,若非
id点不是根节点的直接子节点,且这两个点isLinked(),那么我们就成功发现了一个环,此时计算一下它的长度更新最小环的数据。 -
若两个点都不是
id 查最短路径生成树,若两个点位于不同的子树上,且这两个点
isLinked(),那么我们就成功发现了一个环,此时计算一下它的长度更新最小环的数据。
-
-
测试
本单元测试的测试由于不涉及多层递归深入,也不涉及时序问题,所以难度比表达式解析和电梯调度要小很多,关键是测试数据集的全面,虽然代码支持了很多不同指令,但是我们可以先将指令分类,然后依次编造数据检验。当然由于本单元有给出 规格描述,因此可以简化方法彼此直接数学逻辑的检查测试,更多检验自己实现的方法是否完全符合 规格描述。
白箱黑箱
- 白箱测试
- 方法:理清逻辑漏洞、编造数据、精准攻击
- 不足:由于白箱测试是需要人脑全程制作,这就导致如果一个 bug 是人脑都没有意识到的,那么白箱就很难测不出来。此时,依赖于黑箱的海量测试数据,才有可能测试出来。
- 黑箱测试
- 方法:
- 数据量一定要大,最好是在极限数据量左右
- 用参数去控制生成器行为,比如限定生成器的生成指令的种类,数量等等
- 由于黑箱测试大多数偏向于随机生成数据,或者数据逻辑相对比较简单,因此测试时漏洞覆盖率未必比白箱测试全面。
- 方法:
通过对比白箱测试和黑箱测试的优缺点,我们发现最优的测试方法是“ 白箱黑箱协作测试 ”。
数据构造
在研讨会上,我的小组中的王艺杰大佬分享了他对于测评机数据构造的感想,以下我大致整理了几点注意点:
-
避免数据量看起来大,但其实一堆都是无效数据的情况。
比如举个极端的例子:仅生成了一个
ap指令,也就是整个图只有一个节点,但是却有9999条加边的指令,那这个数据量,看着10000条也挺大的,但其实还不如随便手捏几条数据的强度高。 当然这只是为了便于读者理解我的意思举的一个极端的例子,事实上肯定不会极端到如此地步。
-
那么如何避免这种情况呢?
- 首先给
ap指令设置一个不低的概率,因为没有节点的话别的所有指令都将没有意义。 - 在此基础上,每次
ar、mr时以一个很大的概率从已经ap过的人(而不是在int范围内随机生成俩id去进行操作,int范围太大了,这样生成的id基本就是无效id,会出发异常)中挑两个来进行“边操作”;mr还可以挑两个之间有边的人进行修边操作,之所以是"一个很大的概率"而不是百分百的概率,是因为还要测异常情况,留一小部分概率给异常,可以让测试的覆盖面更广。
这样一来,大多数指令就是有意义的指令了。
- 首先给
-
-
要避免稀疏图的情况。
其实这一点的解决策略和上一条有点重复了。有的测试点,虽然看起来指令不少,但是实际上这个数据点所构建出来的图是非常稀疏的,这就会导致很多情况测不到,比如
qci判断两个点是否连通,那要是这个图很稀,几乎随便俩点都不连通,那其实qci的正确性就不能充分得到测试(当然,稀疏可能也有好处, 一些情况的测试可能需要构建稀疏图, 还是说我们的数据生成器的参数可以随时调整, 我们调整出不同版本的生成器进行多方位强测即可)。-
那么如何让生成器生成稠密图呢?
方法就是把
ap指令的概率调大,然后ar指令的概率调大,且ar的概率要比ap大一个档次,且ar的时候要大概率在已经存在(或者甚至是已经存在且没边)的两个人中间加边, 这样就可以得到稠密图,稠密图测试点可以覆盖相当多的bug情况。
-
-
避免群人数不够多的情况。
群人数够多才能测到群人数的限制。
-
那么如何能增加群人数呢?
数据生成器生成 建群
Group指令 的概率要调小,同时 加人指令和 把人加进群的指令 的数量要调的足够多,这样才能构建出"大群"的情况。
-
-
避免图稠密但是图的规模小的情况。
通过上面的第2条,我们知道了构建稠密图的方法,但是仍然还是无法保证在稠密的同时,图的规模足够大(规模大,肯定能覆盖很多情况)
-
那么如何图规模足够大的稠密图呢?
方法是调大指令的总条数,类似于“相似三角形 等比例扩大”,各个指令都变多了,1k个节点的图,我们可以用10w、20w、50w…的数据量来保证以这么多节点仍然能构造出稠密图,虽说强测限制1w条,但是我们本地测可没限制呀,我之前竟是忽略了这一点的,自己在强测前就应该用十万、百万级的数据狠狠地测!
-
Jconsole插件 + Junit插件
-
IDEA 中自带的 插件,它可以帮助检查CPU时间超时的问题 ,令我比较意外的是:原来 插件检查CPU时间不仅可以用在包含时序问题的代码中,也可以用于测试大规模非多线程代码的CPU时间。
关于 插件的使用方法,详见我之前的博客:BUAA-OO-第二单元:电梯调度
本人在HW11中有一个强测数据点CPU超时了,一开始我始终查不到究竟是哪里导致CPU超时,后来尝试使用 插件才最终缩小范围定位到错误(该错误后续会具体讲述)。这也启示我之后再编写单线程代码之后,也可以用该插件测测CPU时间,以防爆掉。
-
IDEA 中自带的 插件,它是一个单元测试包,可以通过编写单元测试类和方法,来实现对类和方法实现正确性的快速检查和测试。还可以查看测试覆盖率以及具体覆盖范围(精确到语句级别),以帮助编程者全面无死角的进行程序功能测试。
关于 插件的使用方法,课程组给了两个博客教程:
强测互测
强测的Bug
-
Bug1
本单元三次作业中,HW11我被强测测试出一个
CPU_TIME_LIMIT_EXCEED,通过 插件的帮助,最终定位出我错在public int queryLeastMoments(int id)方法中,我 方法求出最短路径树之后,需要遍历所有在不同子树的相互连接的Person,找出最小环。在遍历时,我一开始使用的 的算法,遍历了两遍所有people集合中的人,查它们是否isLinked(),该做法并不是最优的。-
修改方法:
外层循环遍历
people集合中的所有人,内层循环遍历外层循环遍历person的所有acquaintance,由于整个人群集合是一定非常巨大的,但是每个人能认识的熟人却是相对极小的,因此修改后的方法会变成 的时间复杂度。
【合理怀疑小女子写代码的时候脑子短路了,这么明显的一个 算法,我居然会笨到遍历两遍
people集合 呜呜~ 真的是被自己笨到了,大哭ing】 -
-
Bug2
本单元还有一个bug我实在HW11测试时发现,令我捏一把汗的是HW9、HW10的4轮强测和互测都没有测试出来,现在想来都瑟瑟发抖。
具体问题是:在题目代码中,并没有给出
id的数据范围限制,所以我们应该认为它是整个int范围内的。但是,我在编写代码的时候,涉及到一个判断条件需要满足:保证所有id都不等于那个值。而在我前两次作业中,我默认了它的所有id都是大于等于0的。-
修改方法:
把
id包装成Integer类型,用null来表示 “保证所有id都不等于该值” 这个条件。
在此,简单建议明年的助教大佬们,可以注意一下增加这方面的测试点
-
互测的hack
由于本单元提供了 规格描述,因此同学们的代码大多非常完美,很难hack到同一房间的同学,这里我给出自己在三次作业中所有hack到的数据点:
- 有同学
==和.equals()理解不清晰,使用错误,例如:使用==来简单判断Integer类型的两个变量数值是否相同; - 有同学对于
HashMap容器,在加入某<key , value>之前,先进行了.get( key ),导致异常报错,建议可使用.containsKey( key )提前判断一下; - 有同学在
queryLeastMoments方法求解最短路径的时候,开的dis[]、vis[]等数组开的太小了,导致人数超过数组大小之后,代码抛出异常。
后记
第三单元总体来说是比较简单的,这也是一个同学们拉回分数的单元(比如我这种前两个单元做得不理想的),一定不要因为它看上去简单,而不细心揣摩,因为本单元作业实际上蕴含了很多易错的小点。
当然,本单元最大的收获还是第一次入门了解 规格化设计,它不仅是一种帮助验证程序正确性的辅助工具,更要明白它对于一些复杂且重要系统(例如:航空航天控制系统)的重要性,因为我们在一些场景下,是无法通过编造测试数据来实现测试全覆盖的,此时规格化设计便是最好的检测方法。


