BUAA-OS-lab1
Lab1实验报告
思考题
Thinking 1.1
请阅读附录中的编译链接详解,尝试分别使用实验环境中的原生 x86 工具 链(gcc、ld、readelf、objdump 等)和 MIPS 交叉编译工具链(带有 mips-linux-gnu前缀),重复其中的编译和解析过程,观察相应的结果,并解释其中向 objdump 传入的参 数的含义。
-
解:
-
objdump格式:1
2objdump -DS 要反汇编的目标文件名 > 导出文本文件名
/*反汇编所有section,并反汇编出源代码。*/-D:反汇编所有的section;-d:反汇编那些特定指令机器码的section;-S:尽可能反汇编出源代码,尤其当编译的时候指定了-g这种调试参数时,效果比较明显,隐含了-d参数;-s:显示指定section的完整内容。默认所有的非空section都会被显示。
-
-
编写程序
hello.c1
2
3
4
5
6
int main()
{
printf("Hello World!\n");
return 0;
} -
执行指令
gcc -E hello.c(只预处理)+ 重定向输出1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25/* 由于原输出太长,这里只能留下很少很少的一部分。 */
typedef unsigned char __u_char;
typedef unsigned short int __u_short;
typedef unsigned int __u_int;
typedef unsigned long int __u_long;
typedef signed char __int8_t;
typedef unsigned char __uint8_t;
typedef signed short int __int16_t;
typedef unsigned short int __uint16_t;
typedef signed int __int32_t;
typedef unsigned int __uint32_t;
typedef signed long int __int64_t;
typedef unsigned long int __uint64_t;
extern struct _IO_FILE *stdin;
extern struct _IO_FILE *stdout;
extern struct _IO_FILE *stderr;
extern int printf (const char *__restrict __format, ...);
int main()
{
printf("Hello World!\n");
return 0;
} -
执行指令
gcc -c hello.c(只编译不链接)+objdump1
2
3
4
5
6
7
8
9
10
11
12
13hello.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: bf 00 00 00 00 mov $0x0,%edi
9: e8 00 00 00 00 callq e <main+0xe>
#本该填写 printf 地址的位置上被填写了一串 0。
e: b8 00 00 00 00 mov $0x0,%eax
13: 5d pop %rbp
14: c3 retq -
执行指令
gcc -o hello.c(正常编译)+objdump1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21hello: file format elf64-x86-64
Disassembly of section .init:
00000000004003a8 <_init>:
4003a8: 48 83 ec 08 sub $0x8,%rsp
4003ac: 48 8b 05 0d 05 20 00 mov 0x20050d(%rip),%rax
4003b3: 48 85 c0 test %rax,%rax
4003b6: 74 05 je 4003bd <_init+0x15>
4003b8: e8 43 00 00 00 callq 400400 <__gmon_start__@plt>
#填写printf地址处填写了puts@plt标记的位置
4003bd: 48 83 c4 08 add $0x8,%rsp
4003c1: c3 retq
Disassembly of section .plt:
00000000004003d0 <puts@plt-0x10>:
4003d0: ff 35 fa 04 20 00 pushq 0x2004fa(%rip)
4003d6: ff 25 fc 04 20 00 jmpq *0x2004fc(%rip)
4003dc: 0f 1f 40 00 nopl 0x0(%rax)
#......
**对于拥有多个 c 文件的工程来说,编译器会首先将所有的 c 文件以文件为单位,编译成.o 文件。最后再将所有的.o 文件以及函数库链接在一起,形成最终的可执行文件。**如下图:
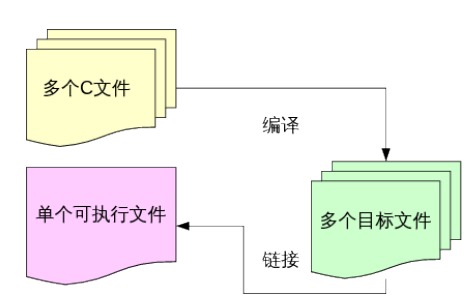
-
-
Thinking 1.2
思考下述问题:
• 尝试使用我们编写的 readelf 程序,解析之前在 target 目录下生成的内核 ELF 文 件。
• 也许你会发现我们编写的 readelf 程序是不能解析 readelf 文件本身的,而我们刚 才介绍的系统工具 readelf 则可以解析,这是为什么呢?(提示:尝试使用 readelf -h,并阅读 tools/readelf 目录下的 Makefile,观察 readelf 与 hello 的不同)
-
解:
-
运行
./tools/readelf/readelf ./target/mos指令得:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
170:0x0
1:0x80010000
2:0x80011cc0
3:0x80011cd8
4:0x80011cf0
5:0x0
6:0x0
7:0x0
8:0x0
9:0x0
10:0x0
11:0x0
12:0x0
13:0x0
14:0x0
15:0x0
16:0x0 -
-
运行
readelf -h readelf指令得:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20ELF 头:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
类别: ELF64
数据: 2 补码,小端序 (little endian)
Version: 1 (current)
OS/ABI: UNIX - System V
ABI 版本: 0
类型: DYN (Position-Independent Executable file)
系统架构: Advanced Micro Devices X86-64
版本: 0x1
入口点地址: 0x1180
程序头起点: 64 (bytes into file)
Start of section headers: 14488 (bytes into file)
标志: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 13
Size of section headers: 64 (bytes)
Number of section headers: 31
Section header string table index: 30 -
运行
./readelf readelf指令无任何输出结果 -
Makefile中对于helloreadelf的生成分别是:1
2
3
4readelf: main.o readelf.o
$(CC) $^ -o $@
hello: hello.c
$(CC) $^ -o $@ -m32 -static -ghello是静态的-static
-
-
Thinking 1.3
在理论课上我们了解到,MIPS 体系结构上电时,启动入口地址为 0xBFC00000 (其实启动入口地址是根据具体型号而定的,由硬件逻辑确定,也有可能不是这个地址,但 一定是一个确定的地址),但实验操作系统的内核入口并没有放在上电启动地址,而是按照 内存布局图放置。思考为什么这样放置内核还能保证内核入口被正确跳转到? (提示:思考实验中启动过程的两阶段分别由谁执行。)
-
解:
-
bootloader 将内核可执行文件拷贝到内存中,之后将控制权交给操作系统,只需要启动入口地址为 bootloader 的入口地址。
-
我们的实验次采用 GXemul 。GXemul 支持加载ELF格式内核,所以启动流程被简化为加载内核到内存,之后跳转到内核的入口。
-
由 Linker Script (控制加载地址)完成。Linker Script 可以控制各节的加载地址。我们在
kernel.lds中设置了程序各个生成地址:1
2
3
4
5
6
7
8
9SECTIONS {
. = 0x80010000;
.text : { *(.text) }
.data : { *(.data) }
.bss : { *(.bss) }
bss_end = .;
. = 0x80400000;
end = . ;
}通过这个控制,生成的程序各个 section 的位置就被调整到了我们所指定的地址上。 segment 是由 section组合而成的,section 的地址被调整了,那么最终 segment 的地址也会相应地被调整。 至此,我们通过
lds文件控制各段(包括内核)被加载到我们预期的位置。与此同时kernel.lds规定了ENTRY(_start),即把内核入口定为_start这个函数。 -
我们通过对
/init/start.S中_start函数的设置,就可以正确的跳转至mips_init函数:1
2
3
4
5
6EXPORT(_start)
.set at
.set reorder
mtc0 zero, CP0_STATUS
li sp, 0x80400000
jal mips_init
-
-
难点分析
-
反汇编:
1
objdump -DS 要反汇编的目标文件名 > 导出文本文件名
-
获得文件类型:
1
file 要查看类型的目标文件名
-
ELF包含三种文件类型:
可重定位文件
relocatable、可执行文件executable、共享对象文件shared object -
ELF文件结构:ELF头 + 段头表segment + 节头表section
-
段头表segment :运行时刻使用
组成可执行文件或者可共享文件,在运行时为加载器提供信息
-
节头表section:编译和链接时刻使用
组成可重定位文件,参与可执行文件和可共享文件的链接
- 在链接过程中,目标文件被 看成节的集合,并使用节头表来描述各个节的组织。换句话说,节记录了在链接过程中所需要的 必要信息。其中最为重要的三个节为
.text、.data、.bss。这三个节的意义是必须要掌握的:.text保存可执行文件的操作指令;.data保存已初始化的全局变量和静态变量;.bss保存未初始化的全局变量和静态变量。
- 在链接过程中,目标文件被 看成节的集合,并使用节头表来描述各个节的组织。换句话说,节记录了在链接过程中所需要的 必要信息。其中最为重要的三个节为
-
-
Offset代表该段(segment)的数据相对于 ELF 文件的偏移。VirtAddr代表该段最终需要被加载到内存的哪个位置。FileSiz代表该段的 数据在文件中的长度。MemSiz代表该段的数据在内存中所应当占的大小。Section to Segment mapping表明每个段各自含有的节。MemSiz永远大于等于FileSiz。若MemSiz大于FileSiz,则操作系统在 加载程序的时候,会首先将文件中记录的数据加载到对应的VirtAddr处。之后,向内存 中填 0, 直到该段在内存中的大小达到MemSiz为止。 -
虚拟地址(virtual address)= 程序地址(program address)= 逻辑地址
物理地址(physical address)
-
区域名称 可用状态 大小 地址变化 是否cache kseg2
0xC0000000-0xFFFFFFFF内核态 1GB MMU中的TLB 通过cache kseg1
0xA0000000-0xBFFFFFFF内核态 512MB 高三位清零 不过 kseg0
0x80000000-0x9FFFFFFF内核态 512MB 最高位清零 通过cache kuseg
0x00000000-0x7FFFFFFF用户态+内核态 2GB MMU中的TLB 通过cache 在
include/mmu.h里有我们的 MOS 操作系统内核完整的内存布局图,其 中KERNBASE是内核镜像的起始虚拟地址,即0x80010000。 -
大小端数据存储方式:
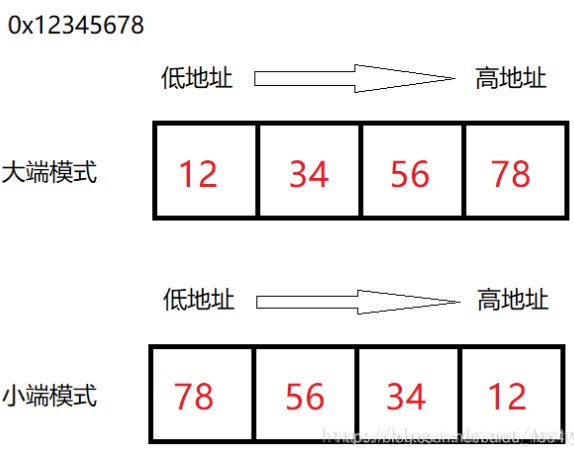
数据在存储空间内的存储位置不发生变化。所以我们在处理大端文件时,取出数据的位置与小端无异,只是需要将取出的数据进行大小端转换进行。
-
大小端转换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
(( (uint16)(A) & 0x00ff) << 8))
(( (uint32)(A) & 0x00ff0000) >> 8) | \
(( (uint32)(A) & 0x0000ff00) << 8) | \
(( (uint32)(A) & 0x000000ff) << 24))
//或
int little2big(int le) { //小端转大端
return (le & 0xff) << 24
| (le & 0xff00) << 8
| (le & 0xff0000) >> 8
| (le >> 24) & 0xff;
}
int big2little(int be) //大端转小端
{
return ((be >> 24) &0xff )
| ((be >> 8) & 0xFF00)
| ((be << 8) & 0xFF0000)
| ((be << 24));
} -
判断大小端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int is_byteorder(int* p)
{
return *(char*)p;//强制类型转换,将精度跳得更高一点
}
int main()
{
int n = 1;
int ret = is_byteorder(&n);
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
-
-
当函数参数列表末尾有省略号时,该函数即有变长的参数表。
stdarg.h头文件中为处理变长参数表定义了一组宏和变量类型如下:-
va_list,变长参数表的变量类型; -
va_start(va_list ap, lastarg),用于初始化变长参数表的宏 (lastarg为该函数最后一个命名的形式参数); -
va_arg(va_list ap, 类型),用于取变长参数表下一个参数的宏;例如:
1
2int num;
num = va_arg(ap, int); -
va_end(va_list ap),结束使用变长参数表的宏。
应用示例:
1
2
3
4
5
6void printk(const char *fmt, ...) {
va_list ap;
va_start(ap, fmt);
vprintfmt(outputk, NULL, fmt, ap);
va_end(ap);
} -
-
readelf的基本用法:
1
2
3readelf -S 编译产物的文件名 //用处查看编译产物的节的位置
readelf -S 编译产物的文件名 //用处查看编译产物的入口的是否被正确设置
//(先看“入口”,再看下面哪个函数的地址和“入口”一样) -
GXemul用法:
1
make dbg 后 unassemble //把pc位置的内存反汇编为汇编,第一句则是入口
-
vim使用技巧
-
命令模式下,
/word文件下寻找一个名称为word的字符串。 -
可视模式下,用鼠标
输入 作用 d 剪切选择文本 y 复制选择文本 p 粘贴选择文本 u 复原前一个动作
-
实验体会
Exercise 1.1
阅读 tools/readelf 目录下的 elf.h、readelf.c 和 main.c 文件,并补全 readelf.c 中缺少的代码。readelf 函数需要输出 ELF 文件中所有节头中的地址信息,对 于每个节头,输出格式为 “%d:0x%x\n”,其中的 %d 和 %x 分别代表序号和地址。
正确完成 readelf.c 之后,在 tools/readelf 目录下执行 make 命令,即可生成可 执行文件 readelf,它接受文件名作为参数,对 ELF 文件进行解析。可以执行 make hello 生成测试用的 ELF 文件 hello,然后运行 ./readelf hello 来测试 readelf。
-
【下图写错了应该都是节头表】
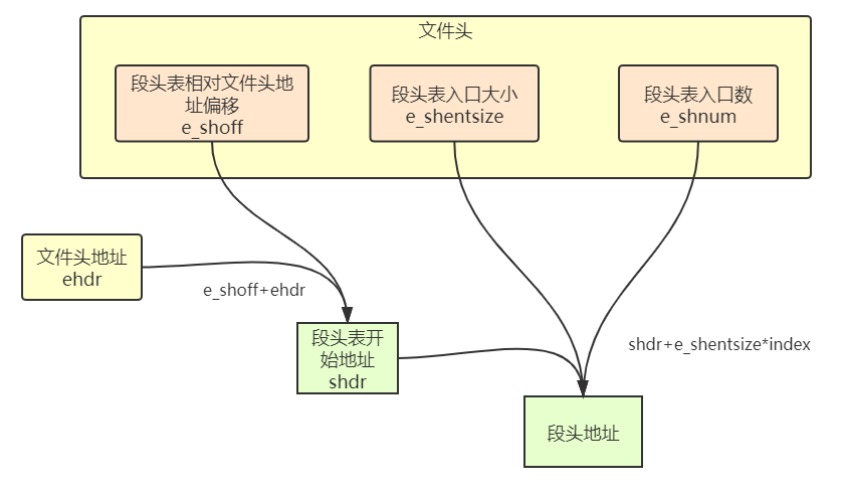
Elf32_Ehdr是ELF文件头;Elf32_Shdr是section节头表表项;Elf32_Phdr是segment段头表表项;- 一个节头表是很多个节头表表项组成;
- 节 不等于 节头 不等于 节头表 不等于 节头表表项
- 文件头的e_shoff是节头表所在处与文件头的偏移; 节头表表项的sh_offset是节的文件内偏移;
- 文件头的e_shentsize是节头表表项的大小; 节头表表项的sh_entsize是指:某些节的内部是一个表,那个表的表项大小是 sh_entsize,并不是节头表项的大小。
-
我的答案:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25//......
int readelf(const void *binary, size_t size) {
Elf32_Ehdr *ehdr = (Elf32_Ehdr *)binary;//ehdr是ELF程序头地址
//...
// Get the address of the section table, the number of section headers and the size of a
// section header.
const void *sh_table;
Elf32_Half sh_entry_count;
Elf32_Half sh_entry_size;
/* Exercise 1.1: Your code here. (1/2) */
sh_table = binary + ehdr->e_shoff; //节头表第一项的地址
sh_entry_count = ehdr->e_shnum; //节头表一共有多少项
sh_entry_size = ehdr->e_shentsize; //节头表每一项是多大
// For each section header, output its index and the section address.
// The index should start from 0.
for (int i = 0; i < sh_entry_count; i++) {
const Elf32_Shdr *shdr;
unsigned int addr;
/* Exercise 1.1: Your code here. (2/2) */
shdr = (Elf32_Shdr*)(sh_table + i*sh_entry_size); //当前要输出的节头项
addr = shdr->sh_addr; //待输出的节头项地址
printf("%d:0x%x\n", i, addr);
}
return 0;
} -
PS:
我们在运行自己编写的
readelf时,要在前面加上./,否则会默认运行一个随编译工具链提供的工具,因为它也叫readelf,它是用来解析一个或者多个 ELF 文件的信息。我们可以通过它的选项来控制显示哪些信息,用法:1
readelf [option(s)] <elf-file(s)>
例如:
readelf -S hello当我们不确定自己编写的
readelf.c文件是否正确的时候,可以用上述readelf来验证。
Exercise 1.2
填写 kernel.lds 中空缺的部分,在 Lab1 中,只需要填补.text、.data 和.bss 节,将内核调整到正确的位置上即可。
-
程序执行的第一条指令的地址称为入口 地址(entrypoint)。我们的实验就在
kernel.lds中通过ENTRY(_start)来设置程序入口为_start。 -
我的答案:
1
2
3
4
5
6
7
8
9
10
11
12
13SECTIONS {
/* Exercise 3.10: Your code here. */
/* fill in the correct address of the key sections: text, data, bss. */
/* Exercise 1.2: Your code here. */
. = 0x80010000;
.text : { *(.text) }
.data : { *(.data) }
.bss : { *(.bss) }
bss_end = .;
. = 0x80400000;
end = . ;
} -
PS:
注意 Linker Script 文件编辑时“=”两边的空格哦!
Exercise 1.3
完成 init/start.S 中空缺的部分。设置栈指针,跳转到 mips_init 函数。
执行 gxemul -E testmips -C R3000 -M 64 target/mos 运行仿真,其中 target/mos 是我们构建生成的内核 ELF 镜像文件的路径。
在我们的实验中,也可以使用命令 make run 来运行 GXemul,或使用命令 make dbg 在调试模式下运行 GXemul。
-
我的答案:
1
2
3
4
5
6
7
8
9
10
11
12
13EXPORT(_start) #函数声明
.set at #允许汇编器使用 at 寄存器
.set reorder #允许对接下来的代码进行重排序
/* disable interrupts */
mtc0 zero, CP0_STATUS #禁用了外部中断
/* hint: you can reference the memory layout in include/mmu.h */
/* set up the kernel stack */
/* Exercise 1.3: Your code here. (1/2) */
li sp, 0x80400000 #由mmu.h得到stack的起始地址为0x80400000
/* jump to mips_init */
/* Exercise 1.3: Your code here. (2/2) */
jal mips_init -
通过
grep搜索,我们可以在init/init.c中发现mips_init函数。
Exercise 1.4
阅读相关代码和下面对于函数规格的说明,补全 lib/print.c 中 vprintfmt() 函数中两处缺失的部分来实现字符输出。第一处缺失部分:找到% 并分析输出格式; 第二处 缺失部分:取出参数,输出格式串为
%[flags][width][length]的情况。
-
重点变量:
1
2
3
4
5int width; // 标记输出宽度
int long_flag; // 标记是否为 long 型
int neg_flag; // 标记是否为负数
int ladjust; // 标记是否左对齐
char padc; // 填充多余位置所用的字符
-
当 Exercise 1.2 、 Exercise 1.3 、 Exercise 1.4 都完成的时候,可以用
make && make run来检验它的结果是否正确,若正确应该输出:1
init.c: mips_init() is called
make test lab=x_y: 装载 labx 的第 y 个测试用例,编译出相应的内核 ELF ,之后使用 make run 可查 看运行结果是否符合预期 示例:make test lab=1_2 && make run
体会与感想
lab1花费时间与lab0相似,由于实验平台仍不太熟悉,补充代码前依旧迟迟不敢开始。在实现printf时需要阅读三个文件的代码,切换起来有些不方便,导致浪费了较多时间。
在后续编写实验报告的时候,我突然意识到:对tmux的使用非常熟悉,完全忘记了可以使用分屏来看代码,而不是傻乎乎地一次次切换!
阅读发现,文件的每一个代码段,都大量使用宏定义和一些全局变量,需要手动grep去查找,虽然说这样是为了代码的可移植性,容错性更高,但是在实际阅读时仍然对于很多宏理解不清楚甚至混淆。
给出的代码一般都预先定义好了变量,但由于不能理解变量名称(比如不知道带ptr的变量是指针),我在面对一块待补充的部分时有些茫然,在学习了一些变量命名规范后发现给出的变量名已经暗中提示了相关的操作,甚至提示了变量的数据类型。
填补代码不仅仅意味着会填所缺陷的代码就完工了,往往先要学习了解较多的预置知识,并且弄清楚其他的文件、宏定义、函数,了解各个文件、函数之间的层次关系,相较于以前一个C程序就可以解决的问题,我们还是需要明晰多文件是如何划分的,它们又是怎么协同完成操作系统的启动的。
课上测试
经过两次上机测试,悟出一个道理:从本届(21级)开始OS课程大幅度改版,于是和往年上机题几乎完全不一样,往年题参考价值大幅度下降,甚至重点考点也会有些许变化。【莫问小女子如何得知,问就是血的教训~】
lab1课上测试我依旧是过了lab1-exam,但是lab1-extra只得了75分,下面具体阐释一下有关lab1-extra的注意点:
lab1-extra
题目:模仿 printk 函数的实现,来完成函数 sprintf 。
知识点:回调函数
-
callback函数的作用:复用相同代码
-
vprintfmt和data参数的作用:传递callback执行上下文信息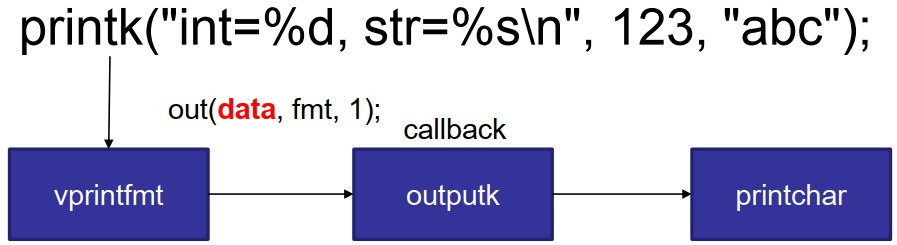
-
在
lib/print.c中,1
2void vprintfmt(fmt_callback_t out, void *data, const char *fmt, va_list ap) {
} -
在
include/print.h中,1
typedef void (*fmt_callback_t)(void *data, const char *buf, size_t len);
printk中使用printcharc函数,通过使用命令:1
grep -R printcharc #-R的意思是在多个子目录中找
得到在
kern/console.c中的函数printcharc的具体实现代码:1
2
3
4
5//printcharc.c
void printcharc(char ch) {
*((volatile char *)(KSEG1 + DEV_CONS_ADDRESS + DEV_CONS_PUTGETCHAR)) = ch;
//volatile是易变的 该语句是向某内存地址写入的一条语句
} -
答案
对于 printk 中使用 printcharc 函数来说,它使用的串口赋值,可以让它每次输出之后,由硬件来自动实现后移一位;但是对于 sprintf 来说,它没有这样的后移功能,因此我们要考核的关键就是——实现指针后移。
1 | //answer |
我的错误
我一共在整个解答过程中犯了2个错误,其中第一个错误幸运地解决了,但是第2个错误上级过程中没有解决得了。
我的错误代码:
1 | //wrong code |
-
错误1:
在编写回调函数的时候,
sprintf函数的回调函数,不可以与printk函数的回调函数outputk同名,必须重新定义一个新的名字,例如outputnew,否则在make的时候,会编译报错(当然我们也要学会看编译报错信息,来判断自己究竟是哪里出错了,【注意多往上看几行,outputk重复命名就报错在倒数第7行,不仔细看容易被忽略】)。 -
错误2:
理解错误
sprintf函数的作用!在考场上,我以为是buf里面是要解析的格式串,并返回buf串前后改变的字符个数,实际上正确的函数作用应该是——解析fmt的格式串,将原本该输出的结果不放在stdout标准输出里面,而是直接覆盖掉原来的buf内容,并输出到buf串里面,返回buf长度(不包括\0)。 我的代码在后续助教的帮助下,正确修改成如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//correct code
void outputknew(void *data, const char *buf, size_t len) {
int i = 0;
while (((char*)data)[i] != '\0') {
i++;
}
for (int j = 0; j < len; j++){
((char*)data)[i] = buf[j];
i++;
}
((char *)data)[i] = '\0';
return;
}
int sprintf(char *buf, const char *fmt, ...) {
va_list ap;
va_start(ap, fmt);
buf[0] = '\0';
vprintfmt(outputknew, buf, fmt, ap);
va_end(ap);
return strlen(buf); //本身strlen函数就不包括\0
}





